
반응형
Machine Learninng algorithm brief review

- Example 1 - spam filtering
- T : 스팸메일을 인식
- P : filtering된 스팸메일의 %
- E : 사람이 labeling 한 이메일 데이터베이스
| 1. Linear classifiers & Nonlinear classifiers | |
 |
수신자의 수에 따른 email의 개수로 판단. 수신자가 많아질 수록 spam일 가능성이 높다. |
 |
1을 기준으로 분류시 검은색 부분만큼의 error 발생 |
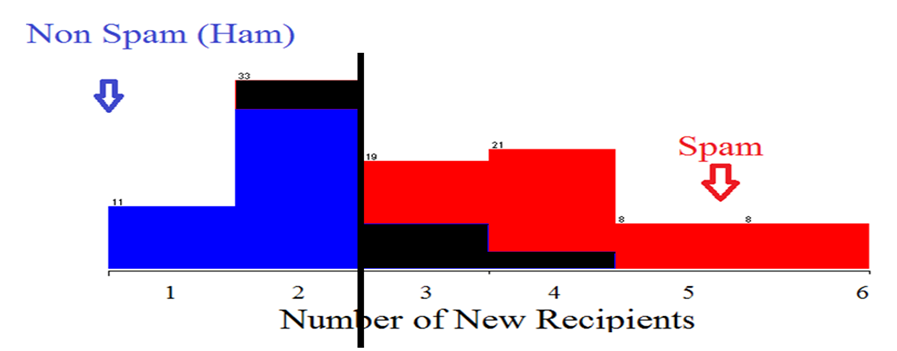 |
2를 기준으로 분류시 검은색 부분만큼의 error 발생 |
 |
수신자 수를 기준으로 할 경우 error가 큼. -> 하나의 feature로는 문제를 완벽하게 해결할 수 없다. feature 추가 : 이메일 길이를 기준으로 spam mail 분류. |
 |
두 feature를 기준으로 spam mail 분류 |
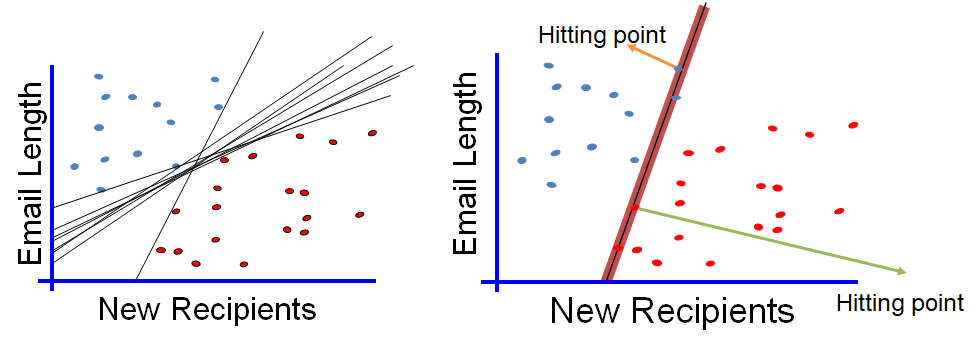 |
최적의 선형분류는 무엇인가?? 우측과 같이 margin이 최대화하는 선형 분류기를 정의 => Linear SVM(Support Vector Machine) 딥러닝 이전의 많이 사용한 ML 모델 |
 |
왼쪽과 같이 예외가 있는 샘플이 있는 경우 Linear classifier를 사용할 수 없다. -> 우측과 같이 비선형 분류기(Nonlinear Classifier)를 사용해야한다. |
* Issue of Generalization |
Training sample이 아닌 Test sample의 성능을 높이는 것이 중요하다. Ptest가 최종 성능이 되어야 한다. => 일반화 이유(Issue of generalization) |
| 2. K-Nearest neighbor classifier | |
 |
o : class 1(부류 1) x : class 2(부류 2) + : test sample(분류할 대상) +와 가장 가까운 sample의 class(부류)로 판정한다. (가장 가까운 sample n개를 선택하여 많은 class로 판정) |
| 3. Classifiers : Linear SVM | |
 |
f(x) = sgn(w × x + b) sgn(a) = 1 a >= 0 -1 a <= 0 우측 그림에서 실선과 점선 사이의 거리를 margin margin이 최대화하는 linear classifier를 정의한다. |
| Linear SVMs using Kernel Trick | |
 |
Linearly separable(선형 분류가능한)하다. |
 |
Linearly separable(선형 분류가능한)불가능. 비선형 분류기를 사용해야 한다. |
 |
하지만, 고차원으로 mapping하여 Linearly separable(선형 분류가능한)하게할 수 있다. => SVM Kernel trick의 핵심 원리 |
 |
General idea: the original input space can always be mapped to some higher-dimensional feature space where the training set is separable |
The kernel trick |
 |
| 4. Decision Tree | |
 |
A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes represent class labels or class distribution |
 |
 |
 |
 |
| 5. Neural Network Model | |
 |
신경망 구조로서 심층 신경망(Deep Neural)의 기본이 된다. sigmoid 활성화 함수(activation function) 사용 |
| 6. Bayes Classifier | |
| * Design classifiers to make decisions subject to inimizing an expected “risk”.(분류에러(rist)를 최소화하도록 결정한다) * 오분류에 따른 위험이 클 수록 misclassification cost가 크다. |
|
 |
w : class(부류)로 표현 P : 사전 확률(배경 지식) p : 확률밀도함수(특징 값-> n차원의 verctor form으로 표현) p(x/w) : 우도, likelihood(class w일 때 x가 발생할 확률) p(w/x) : 사후확률분포, 최종목표는 사후확률을 구하는 것   |
| Decision Rule(판정 규칙) using prior probablities only Decide ω1 if P(ω1) > P(ω2); otherwise decide ω2  사전정보는 시불변(time invariant)하다. |
Decision Rule using conditional probablities only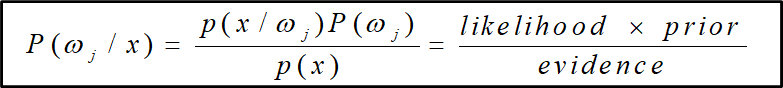   |
Machine Learning Theory and Principles
Generalization(일반화)
- How well does a learned model generalize from the data it was trained on to a new test set?
새로운 dataset에 얼마나 잘 적용되는가(일반화가 잘 되도록 학습) - Components of generalization error
- bias : 모든 training set에 대하여 true model과 설계한 model이 다른 정도
부정확한 가정, 간소화로 인하여 발생하는 에러 - Variance(분산 에러) : 각각 다른 Training dataset에 대하여 에러가 크게 차이가 나는 에러
- bias : 모든 training set에 대하여 true model과 설계한 model이 다른 정도
- Underfitting(저적합)
: Model을 너무 단순화하여 발생한 현상- 높은 bias error 와 낮은 variance error
- 높은 training error 와 높은 test error
- Overfitting(과적합)
: Model을 너무 복잡화해서 발생한 현상, 부적절한 데이터와 잡음까지 학습한 경우- 낮은 bias error 와 높은 variance error
- 낮은 training error 와 높은 test error(일반화되지 않음)
- Bias-Variance Trade-off

모델이 너무 단순(파라미터의 수가 작음)해서 실제 모델의 복잡성을 표현하지 못할경우 저적합 현상 발생.
큰 bias 에러를 갖는다.

모델이 너무 많은 파라미터를 가지고 있어서 variance가 너무 크다.
sample에 대하여 민감도가 높아서 작은 변화에도 모델 성능의 변화가 크다.

반응형
'AI > Machine Learning' 카테고리의 다른 글
| A Tour of Machine Learning (2) - Type of Machine Learning approach (0) | 2020.10.19 |
|---|---|
| A Tour of Machine Learning (1) - What is Machine Learning? (0) | 2020.10.19 |